
Rocket and Rust Part VI (and some barrel aged libations)
At long last! An end to the rocket and rust series... and the beginning of something new!

Happy New Year, everyone! Phew, I had a break! I took care of some family stuff, traveled back to Montana, got a new job, then proceeded to travel to Portland, Las Vegas, Denver, Santa Fe, San Francisco and an emergency trip back to Montana again, all in the space of a few months! Excuses, excuses... Anyway, let's get to it! My goal is to finish this thing so I can store the data for all my liquor collection in 2024!!!
Last time we talked, I had successfully created my database models and schema using the ORM of my choice. All I had left to do was wire up my APIs to my models... or so I thought. Things did not go... as expected. Well, we may as well jump in.
Immediately when I started trying to wire up my models to my APIs as they are, I hit a snag. I mentioned at the end of my last post that "my struct typings on my serialized Bottle struct are going to get me in to trouble". They sure did! Our ORM does not know how to handle a Category when it comes to the database. It's a nested structure with its own values.
At this point I had another decision to make, I could:
- Create some custom code to handle the lookup of categories and other structs behind the scenes when dealing with
Bottleobjects - Change all structs referencing other tables to use id's on their schemas instead
I decided to see just how little code I could write for my APIs, so I decided the latter would be more interesting: offload the referential complexity to my schema and the ORM rather than handle it myself.
Deciding to rely on the ORM means I have to undo a decision I made last time around storing the original Location struct parts on the Bottle struct and eliminating the table. Now we are back to needing some way to store this data again. Preferably not requiring us to create three separate tables and referencing their ids on the Bottle struct. To refresh, here is what the Bottle struct looked like at the end of our last foray:
#[derive(Serialize, Deserialize)]
struct Bottle {
id: u16,
name: String,
category: Category,
sub_category: Vec<SubCategory>,
room: Room,
storage: Storage,
shelf: Shelf,
}Old Bottle Struct
I wasn't keen on the name Location for the previous struct, so I went ahead and decided to just use Storage as the name. I don't love it either, but I find it less strange than Location for some reason. So, we are adding a Storage struct now in order to store the room, storage, and shelf information separately from our Bottle data:
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable)]
#[diesel(table_name = storage)]
pub struct Storage {
pub id: i16,
pub name: String,
pub room: String,
pub shelf: String,
}This also means anywhere we were using our Category, SubCategory, or Storage structs in other structs (such as Category in SubCategory) we updated our code to instead use an id field of the correct type. Our updated structs now look like this:
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable, Identifiable, Associations)]
#[diesel(belongs_to(Category))]
#[diesel(table_name = sub_categories)]
pub struct SubCategory {
pub id: i16,
pub category_id: i16,
pub name: String,
}
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable, Identifiable, Associations)]
#[diesel(belongs_to(Category))]
#[diesel(belongs_to(Storage))]
#[diesel(table_name = bottles)]
pub struct Bottle {
pub id: i16,
pub name: String,
pub category_id: i16,
pub sub_category_ids: Vec<i16>,
pub storage_id: i16,
}Notice the diesel macros I added to the structs! I added these to the other models as well, minus the belongs_to and Associations as those were only necessary where there was a foreign key to our other tables. For more information on Diesel relations macros, check out their excellent documentation! Also take note: there is no belongs_to for SubCategory and the id field is represented as an array/vector (Vec<i16>).
Unfortunately, we hit another snag regarding our array representation of the SubCategory ids. We should be able to have a bottle with no sub categories or many sub categories. Our modeling does not account for this, and will actually throw errors if there are no sub category ids. I went down a deep deep rabbit hole on Diesel vs. Rust types and how to represent the data structure I wanted.
I ended up doing a lot of reading on the Diesel table macro. This helped, as I recognized the idea of Nullable<T> for fields in the database which were not required (or nullable). But what does a Nullable<Array> of Nullable<Int2> look like as a Rust type in a struct? Eventually, my investigation led to the most helpful cheat sheet ever showing the mapping not only of Diesel and Rust types, but also their representation in PostgreSQL! So my Nullable<Array<Nullable<Int2>>> became Option<Vec<Option<i16>>> in the Bottle struct to represent the optional sub category ids! Phew!
Finally our schema file is also updated now post-db migrations! We now have representations for all of our structs which work with the database:
// @generated automatically by Diesel CLI.
diesel::table! {
bottles (id) {
id -> Int2,
name -> Varchar,
category_id -> Int2,
sub_category_ids -> Nullable<Array<Nullable<Int2>>>,
storage_id -> Int2,
}
}
diesel::table! {
categories (id) {
id -> Int2,
name -> Varchar,
}
}
diesel::table! {
storage (id) {
id -> Int2,
name -> Varchar,
room -> Varchar,
shelf -> Varchar,
}
}
diesel::table! {
sub_categories (id) {
id -> Int2,
category_id -> Int2,
name -> Varchar,
}
}
diesel::joinable!(bottles -> categories (category_id));
diesel::joinable!(bottles -> storage (storage_id));
diesel::joinable!(sub_categories -> categories (category_id));
diesel::allow_tables_to_appear_in_same_query!(
bottles,
categories,
storage,
sub_categories,
);
schema.rs after migrations
Alright! We should be all set now, things are compiling, and we can test again! Oh... what happened? My terminal now has compiler linking issues and rustc is vomiting errors all over. I will admit: I panicked. What had I done? Why was everything suddenly broken between one night and the next? Welllllll.... The version of Rocket I have been doing this work in is a release candidate, and required a nightly build of the rust toolchain. A recent nightly had broken my toolchain. All I had to do was run rustup update and all was well! Wanted to share, because sometimes its not always obvious when working on bleeding edge when things have changed. Keep calm, and rust on!
At this point, I really wanted to reorganize my code. So far, everything was in our main.rs file and was getting really verbose and messy. I wanted to organize things into modules as well as library for helper functions. There is an excellent chapter on organizing Rust code in the Rust Classes book which is all online. I highly recommend checking it out if you are new to Rust, or just looking for good references.
Okay, back to organizing our code. My goal was to have a routes module with individual files for each of our top level API routes. I also wanted a distinct module for models and a library file for helper functions as mentioned previously. First, let's pull out our models to their own file:
use serde::{Deserialize, Serialize};
use crate::schema::{storage, categories, sub_categories, bottles};
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable)]
#[diesel(table_name = storage)]
pub struct Storage {
pub id: i16,
pub name: String,
pub room: String,
pub shelf: String,
}
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable, Identifiable)]
#[diesel(table_name = categories)]
pub struct Category {
pub id: i16,
pub name: String,
}
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable, Identifiable, Associations)]
#[diesel(belongs_to(Category))]
#[diesel(table_name = sub_categories)]
pub struct SubCategory {
pub id: i16,
pub category_id: i16,
pub name: String,
}
#[derive(Serialize, Deserialize, Queryable, Debug, Insertable, Identifiable, Associations)]
#[diesel(belongs_to(Category))]
#[diesel(belongs_to(Storage))]
#[diesel(table_name = bottles)]
pub struct Bottle {
pub id: i16,
pub name: String,
pub category_id: i16,
pub sub_category_ids: Option<Vec<Option<i16>>>,
pub storage_id: i16,
}models.rs
Notice we are maintaining a connection to our existing schema module, as our models need access to the schema for our diesel database connection. We also need to make sure we import the serde crate serialization and deserialization we are relying upon for translating our json data from our APIs.
Next let's move some common functions out to a lib.rs. It's not super necessary, but I like the idea of keeping possible common functions outside of the main application file. The only items I abstracted here were the PostgreSQL configuration and the generic error to throw in case of an issue:
use rocket::serde::{Deserialize, Serialize};
use rocket_sync_db_pools::database;
#[database("my_db")]
pub struct Db(diesel::PgConnection);
#[derive(Serialize, Deserialize, Debug)]
#[serde(crate = "rocket::serde")]
pub struct ApiError {
pub details: String,
}
lib.rs
We will do the same decomposition for the routes in our main.rs, leaving only our rocket launch function. Don't forget to import your new modules in your file!
#![feature(decl_macro)]
#[macro_use] extern crate rocket;
#[macro_use] extern crate diesel;
use rocket::Config;
use rocket::fairing::AdHoc;
use ethel::Db;
pub mod schema;
pub mod models;
pub mod routes;
#[launch]
fn rocket() -> _ {
let rocket= rocket::build();
rocket
.attach(AdHoc::config::<Config>())
.attach(Db::fairing())
.mount("/", routes![routes::index])
.mount("/bottles", routes![
// routes::bottles::get_random_bottle,
routes::bottles::create,
routes::bottles::get,
routes::bottles::delete,
routes::bottles::update
])
.mount("/storage", routes![
routes::storage::create,
routes::storage::get,
routes::storage::delete,
routes::storage::update
])
.mount("/categories", routes![
routes::categories::create,
routes::categories::get,
routes::categories::delete,
routes::categories::update
])
.mount("/sub_categories", routes![
routes::sub_categories::create,
routes::sub_categories::get,
routes::sub_categories::delete,
routes::sub_categories::update
])
}
main.rs
So much easier to read! And it's not well over 200 lines any more! Plus, now if I mess something up, hopefully I only mess up one thing and not the entire project 😅. I am glossing over the route file content, as we are about to revisit them one by one, but here is my final file structure for my source code:
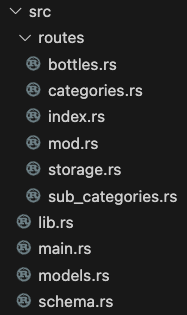
Now the code is organized with working modules! I feel ready to finish wiring up the APIs and seeing code actually go into the database via API. So excited!!! Let's start with our simplest struct, Category:
pub struct Category {
pub id: i16,
pub name: String,
}Category struct excerpt from models.rs
The Category model is simply an id and a name. What could be simpler? Let's write a create endpoint quickly using our Rocket and Diesel macros:
use diesel::{self, prelude::*};
use rocket::{serde::json::Json, response::status};
use crate::models::Category;
use crate::schema::categories;
use crate::Db;
use ethel::ApiError;
#[post("/", data = "<category>")]
pub async fn create(
connection: Db,
category: Json<Category>
) -> Result<status::Created<Json<Category>> , Json<ApiError>> {
connection
.run(move |c| {
diesel::insert_into(categories::table)
.values(&category.into_inner())
.get_result(c)
})
.await
.map(|a| status::Created::new("/").body(Json(a)))
.map_err(|e| {
Json(ApiError {
details: e.to_string(),
})
})
}
Create function for route/categories.rs
Told you we were going to visit route files individually! Our ORM (Diesel) and Rocket are doing a lot of the heavy lifting here. Basically, our first macro is setting up an endpoint accepting a POST request and specifying the data is shaped like our declared Category model. Rocket will return a Result of either a Created status (http status 201) or the default error we setup earlier in our lib.rs.
In the body of our create function, we access our database connection and run a diesel insert command, specifying the table and the values we are inputting from the request, then returning the result. Our code waits for the execution of the db command, then either maps the successful response, or maps the error response.
I like this code. It feels easy to understand, and did not require a great deal of effort to wire up the API and the database. But... does it work? Alas: we have hit another snag. Some of you may have noted our models all had ids on them. But ids are generally generated by the database on insert not provided by the ORM on creation. We get an error immediately when trying to pass data to the DB. This will effect all of our models and their create functions. So what is the solution?
Again, there are a couple of different approaches. I could write some custom handlers for insert. Or, I could rely upon the serialization and strong type support, and simply declare seperate models for "new" version of my data. While I would like to explore the former at a future date, the latter felt like continuing to offload complexity to the ORM which has been my decision thus far. SO! Let's create a NewCategory model and update our existing Category function to remove unneeded macros:
#[derive(Serialize, Queryable, Debug)]
pub struct Category {
pub id: i16,
pub name: String,
}
#[derive(Deserialize, Insertable, AsChangeset, Debug)]
#[diesel(table_name = categories)]
pub struct NewCategory {
pub name: String,
}Excerpt from model.rs showing Category models
Is this overkill for such a simple model? Yeah. Probably. But does it work? Well, let's update our create function for our categories route and try again!
#[post("/", data = "<category>")]
pub async fn create(
connection: Db,
category: Json<NewCategory>
) -> Result<status::Created<Json<Category>> , Json<ApiError>> {
connection
.run(move |c| {
diesel::insert_into(categories::table)
.values(&category.into_inner())
.get_result(c)
})
.await
.map(|a| status::Created::new("/").body(Json(a)))
.map_err(|e| {
Json(ApiError {
details: e.to_string(),
})
})
}Create function from categories.rs
Then let's go try a post with some real data!

Success! Let's double check things look good in our database as well with our DBeaver tool:
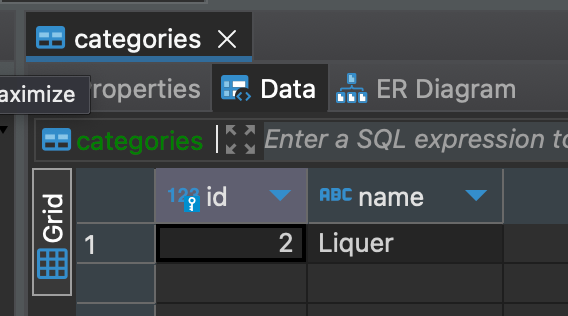
Even more success! Just to recap, we now have a working create API for our categories and the data is being persisted to our PostgreSQL database. Now... You may have noticed... I misspelled "Liquer"! Did I do it on purpose to make our update endpoint more meaningful? Sure, yeah, I definitely did it intentionally. Onward to our update endpoint so we can correct the data!!!
#[put("/<id>", data = "<category>")]
pub async fn update(
connection: Db,
id: i16,
category: Json<NewCategory>
) -> Result<Json<Category>, status::NotFound<Json<ApiError>>> {
connection
.run(move |c| {
let to_update = categories::table.find(id);
diesel::update(to_update)
.set(&category.into_inner())
.get_result(c)
})
.await
.map(Json)
.map_err(|e| {
status::NotFound(Json(ApiError {
details: e.to_string(),
}))
})
}Excerpt from categories.rs showing the update function.
This should look very familiar. Really the only difference between our create and update functions are HTTP verb (PUT instead of POST) and doing a lookup on the categories table for the provided id, before using the data to update it. Something you might notice in this function definition is I am making use of the NewCategory model again here. I did this in order to explicitly call out the id parameter as a part of the route rather than part of the request body. I just as easily could have used the Category model, but I like having the RESTful structure of the id in the update route.
Anyway, let's try and correct our terrible mistake in spelling...
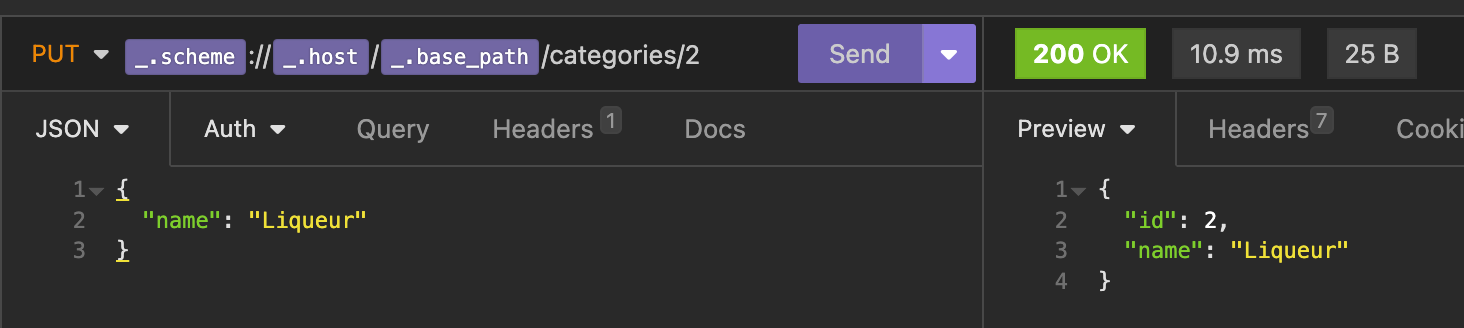
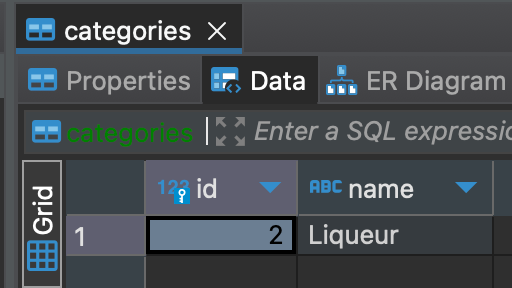
Phew! Crisis averted. Another way we could have fixed our mistake is by deleting the category and creating a new one! In fact, you may have noticed my records started with 2 as the id instead of 1. This is due to some testing I was doing before I took my screenshots (whoops). So lets take a look at what the delete endpoint looks like:
#[delete("/<id>")]
pub async fn delete(
connection: Db,
id: i16
) -> Result<status::NoContent, status::NotFound<Json<ApiError>>> {
connection
.run(move |c| {
let affected = diesel::delete(categories::table.filter(categories::id.eq(id)))
.execute(c)
.expect("Connection is broken");
match affected {
1 => Ok(()),
0 => Err("NotFound"),
_ => Err("???"),
}
})
.await
.map(|_| status::NoContent)
.map_err(|e| {
status::NotFound(Json(ApiError {
details: e.to_string(),
}))
})
}Excerpt from categories.rs showing the delete function.
I originally expected this function to be super short and less verbose... but not so much. I want to get the result of the deletion and then run a match to figure out exactly which result we ended up with: success, couldn't find a record with the provided id, or some other error state. Then it's business as usual, although we return an http status of No Content (204) in this case.
Let's go ahead and try deleting our Liqueur category, even though we fixed it:

Now we have a functional delete API! Our only remaining CRUD action is Read. Let's add a GET for our categories now. To start, I don't really care about getting specific categories, I only want a list of them.
#[get("/")]
pub async fn get(connection: Db) -> Json<Vec<Category>> {
connection
.run(|c| categories::table.load(c))
.await
.map(Json)
.expect("Failed to fetch categories")
}Get categories endpoint excerpt from categories.rs.
Of course, when we test, our list of categories is empty since we deleted our only category:

CRUD complete! Now we only need to add our CRUD operations to each of our different models. I'm not going to cover each of them individually, but I do plan on publishing all of the code to my github. At this point, our basic API is complete! One final item I want to add is a "random bottle" API, which, when called, returns a random bottle from our collection. Before I do this, I want to actually add some data to my database! I will be spending some time in advance of my next post populating my DB.
At this point, I consider my Rocket and Rust series complete! I will definitely come back to this project and post more, particularly once I start fiddling with a UI, but for now, our basic Rust and Rocket API is complete.
Ethel Public Github Project
Release v0.1.0 of Ethel on Github
Russian River Intinction
For those unfamiliar with the word "intinction" (I know I was) it is defined as:
in·tinc·tion
/inˈtiNG(k)SHən/
noun
the action of dipping the bread in the wine at a Eucharist so that a communicant receives both together.
I am frequent drinker of Russian River Brewing. Many folks are familiar with their double IPA, Pliny the Elder. I am actually not nearly as big of a fan of Pliny as I am of their barrel aged brews (some folks will see this as the worst kind of blasphemy, but here we are). Russian River works with local wineries (they are in the Bay Area, so Napa is very near) and uses their barrels to age some of their more interesting beers.
I try every barrel-aged beer I can get my hands on from Russian River. A shop local to me is also a lover of their beers, so I can usually find a bottle or two of every release, for which I am grateful! On this occasion, I snagged a bottle of Intinction. As the name would suggest, wine is involved in the beer beyond just the wine barrel aging process. From the label: "Pilsner aged in Sauvignon Blanc Barrels with Sauvignon Blanc Grapes", and Russian River's site has even more info if you are curious. I am very excited to try this beer.
All of these beers tend toward the sour due to the brettanomyces or lactobacillus in them, which is probably one of the reasons I have liked all of them, actually. Inctinction only has brettanomyces, in this case. I poured my bottle (slowly! there is yeast in the bottom) into a nice glass I have from New Belgium. Russian River usually has a guide to the recommended glass, and Inctinction is no exception. No pint glasses here, you want a tulip.

Pours a lovely straw color, with a slight cloudiness (could be my poor pouring technique, lol). Smells like green apples and tart fruit, just a hint of barrel oakiness on the nose. Tastes like... hmm. Tastes a lot like Sauvignon Blanc wine, actually! Tart fruitiness, with underlying light beer flavor from the pilsner. Definite tannin from the oak, but not a kick in the teeth – none of the drying sensation you get sometimes with a high tannin wine, for example – light in body, and just enough carbonation from the bottle conditioning to really bring up the refreshment level. There is a level of funk, too, which I generally taste in a barreled aged beer using lacto (or in this case, bretta) in the fermentation. Delightfully sour, but not face puckering-ly so. I find this to be a super lovely balance between the wine characteristics and the base of a soured pilsner. Flavor doesn't linger unpleasantly on the palate, but you do feel the tannins at the very back of your tongue between sips.
Winner in my book! 4.5 / 5 stars. I wish I tasted just a bit more beer in it, but I really enjoy the flavor profile. I found out there is another version of Intinction done with Pinot Noir instead of Sauvignon Blanc! I am going to ask my local shop if they plan on stocking it, and perhaps putting in a special request. Cheers!