
Rocket and Rust Part V (and a sip of summer)

Last time on "Rust of our Lives"... Okay, sorry. I remember any time I was home sick from school, my mom would have her "soaps" on. I still have vivid memories from the daytime dramas. Where was I? Oh yeah! Last time on Part IV, I finished creating all of my endpoints for our project Ethel API. Currently the API is using all dummy data. Today, we will correct this by picking a database, picking a connector, and getting our application wired up to use our new database!
Selecting a Database
First things first... What kind of database do we want to use? There are endless (and I really do mean endless) possibilities. Given the nature of the data I am storing, we could do a document style db... but if I add the ability to store and update locations and categories later, we end up with relational data. I know I want to expand my application with additional requirements, so I am going to pick a relational database. I also find adding indexes after the fact to be easier with a relational db than a document style db, but your mileage may vary depending on volume of data and style of index.
Alright so we want relational... At this point, the nature of my data doesn't require bells and whistles. Something we can run locally easily, preferably in a docker container, would be ideal. There are so many options still to pick from, but I am going to use PostgreSQL. It's open source, reliable, and I am very familiar with the technology from multiple past roles. To be clear: I could just as easily have chosen MySQL or something else. At this stage, given my requirements, it's a purely personal choice.
Time to fire up a docker container for out database! I already had Docker installed, so finding a Postgres db image was next. As an aside, I prefer to use Docker to run projects like this instead of on the bare metal locally. Why? Well, honestly, it's super super easy (please read previous examples of my lazyness). There are multiple ways to run our Postgres DB from Docker. I am using an official image from Docker Hub and chose to use a docker-compose.yml file for running my image.
version: '3.1'
services:
db:
image: postgres
restart: always
environment:
POSTGRES_USER: ethel
POSTGRES_PASSWORD: ethel
ports:
- "5432:5432"
docker-compose.yml for Postgres instance
In a real-world application, I would not want those passwords committed to github, obviously, but this is all for fun right now! docker-compose up will pull the image and start our database. We are now ready to connect!
Another aside: I like having a visual representation of my data to play with for debugging. I have used tons of different SQL GUIs (Graphical User Interfaces) over the years, from smaller offerings like Sequel Pro to full blown software suites like Microsoft's SQL Studio. Right now I am fiddling with DBeaver, its free, open source, and does the job. It also happens to support PostgreSQL! Let's connect to our DB and make sure our connection string works before we start talking about how to connect our application.
Success! Onto selecting our connector for our database to our application.
Selecting an ORM (Object-Relational Mapping)
We could just connect directly to our DB and write all of our SQL queries by hand in our Rocket application. I really don't want to do that... one of the alternatives is an ORM, or Object-Relational Mapping. Using an ORM simplifies our data access and manipulation, allowing us to continue writing in our language of choice (in this case, Rust) without having to change languages to SQL. Now, there are dangers in using an ORM if you do not understand the underlying query being constructed. Again, particularly for our small use case, I am not overly concerned by any possible performance losses with an ORM over the simplicity of representing our data more easily.
So which ORM should we choose? Due to the bleeding edge Rust and Rocket are on, there are not as many to choose from as there would be for another more established language. The main two I have been looking at are SeaORM and Diesel. Both seem fairly ubiquitous in their appearance in applications. I found a great article discussing this exact quandary: An Overview of Popular Rust ORMs, written by Ukeje Chukwuemeriwo Goodness. While I strongly encourage to go read the article if you are interested, my TLDR is this: either ORM will work for me.
Due to the more mature nature of Diesel (and huge array of examples, including ones in Rocket's own documentation) this seemed like the path of least resistance. I did actually poke at SeaORM a bit originally, but their documentation is out of sync with their examples. As a non-expert Rustacean, I decided to go back and try Diesel instead 😅.
Installing our new diesel crate dependency is our first order of business. Looking at the documentation for our new ORM, it appears Diesel also has a CLI we can use to generate our configuration and our migrations. So let's add our crates to our Cargo.toml first:
diesel = { version = "2.1.0", features = ["postgres", "r2d2"] }
dotenvy = "0.15"New crate dependencies in Cargo.toml
Our cargo watch -x run picks up our Cargo.toml changes and immediately installs our new crate dependency and restarts our server. Next we will install the Diesel CLI tools using cargo install diesel_cli --no-default-features --features postgres. Make sure to have PostgreSQL installed locally!!! Or you will get an error (like me). You can install Postgres in a number of ways, but I chose homebrew.
Now with the handy CLI tools are installed, we can set some things up! First, we need to create a .env file (you may have noticed the dotenvy crate in our Cargo.toml, this is what we are using it for). The .env will provide our CLI with our database url:
DATABASE_URL=postgres://ethel:ethel@localhost:5432/etheldbMake sure your database exists before running your Diesel commands, or you will get lots of errors! Now we can run diesel setup which creates our migration folder and our initial migration for our database. Let's go ahead and pre-emptively run the command to create a migration for our Bottles table as well: diesel migration generate bottles. Now we have an up and down migration for adding our new table, called bottles! I can open this file and define the same structure I wrote in my struct for the bottle object.
At this point though, I realized I had to make some choices about how I wanted to represent my data. You will recall I currently have Location struct, which is referenced as a location property on the Bottle struct. How do we represent the nested nature of location in our table definition in SQL? We have some choices:
- Create a location table and reference location via foreign key. We would have to remove all of our enum info and force this into our table instead... Not the worst thing in the world, but I was trying to avoid additional tables for now.
- Use Postgres' jsonb fields. We could literally shove a json object into our database with the location information. I'm not sure how this would play with the Diesel and serde serializers, though, and jsonb fields are pretty gross to query.
- Eliminate the
Locationstruct altogether and move the room, storage, and shelf properties up to theBottlestruct instead. It flattens our JSON responses and if we decided to move location to a table later, we are not making things super hard for ourselves (writing a migration for this would be easy).
I decided to go with option 3, as it simplifies our code for now. I have to update quite a few places in our application, but that's okay! Or Bottle struct now looks like so, and the Location struct has been eliminated entirely:
#[derive(Serialize, Deserialize)]
struct Bottle {
id: u16,
name: String,
category: Category,
sub_category: Vec<SubCategory>,
room: Room,
storage: Storage,
shelf: Shelf,
}Updated Bottle struct
Our API response is now also flatter:
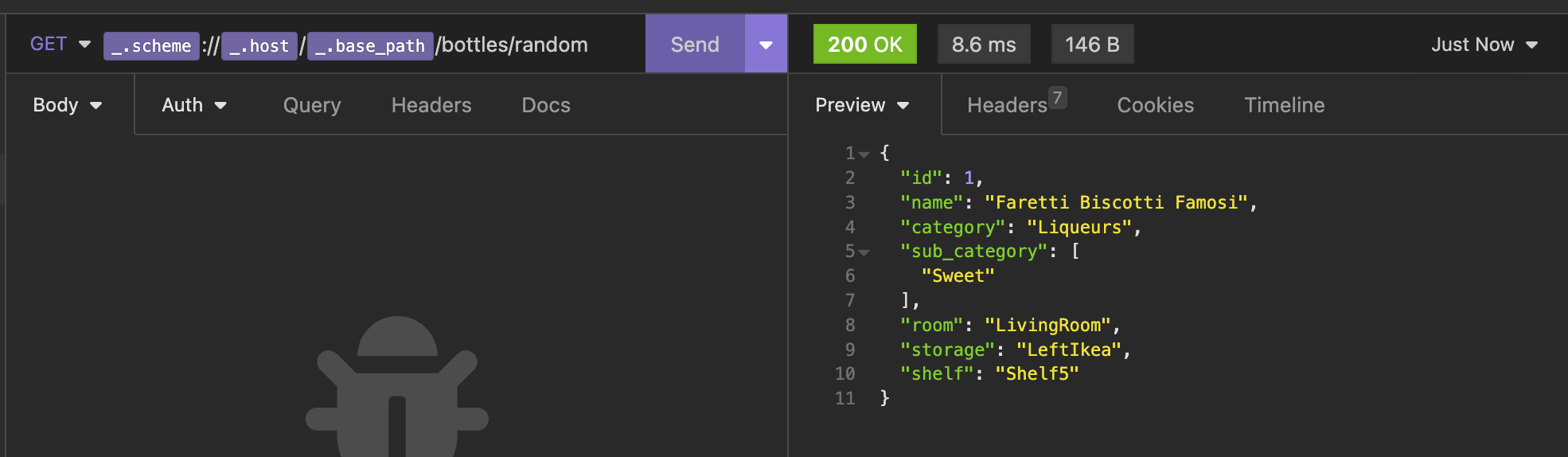
In theory, I should now be able to write an easier migration to setup my bottle table:
CREATE TABLE bottles (
id SMALLSERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
category VARCHAR NOT NULL,
sub_category VARCHAR[],
room VARCHAR,
storage VARCHAR,
shelf VARCHAR
)Bottles table up migration
The down migration is easy: I just need to undo anything done in the up migration.
DROP TABLE bottlesBottles table down migration
Let's test our migrations by running diesel migration run. Oh interesting, immediately I get a warning:

Diesel doesn't like our varchar array field. While I am not a fan of using text array, it looks like for this example we must. Let's go ahead and change our array, then run diesel migration redo which will run our down migration then rerun our up migration with our new field type. And no warnings! Let's double check our table looks as expected in our SQL GUI:
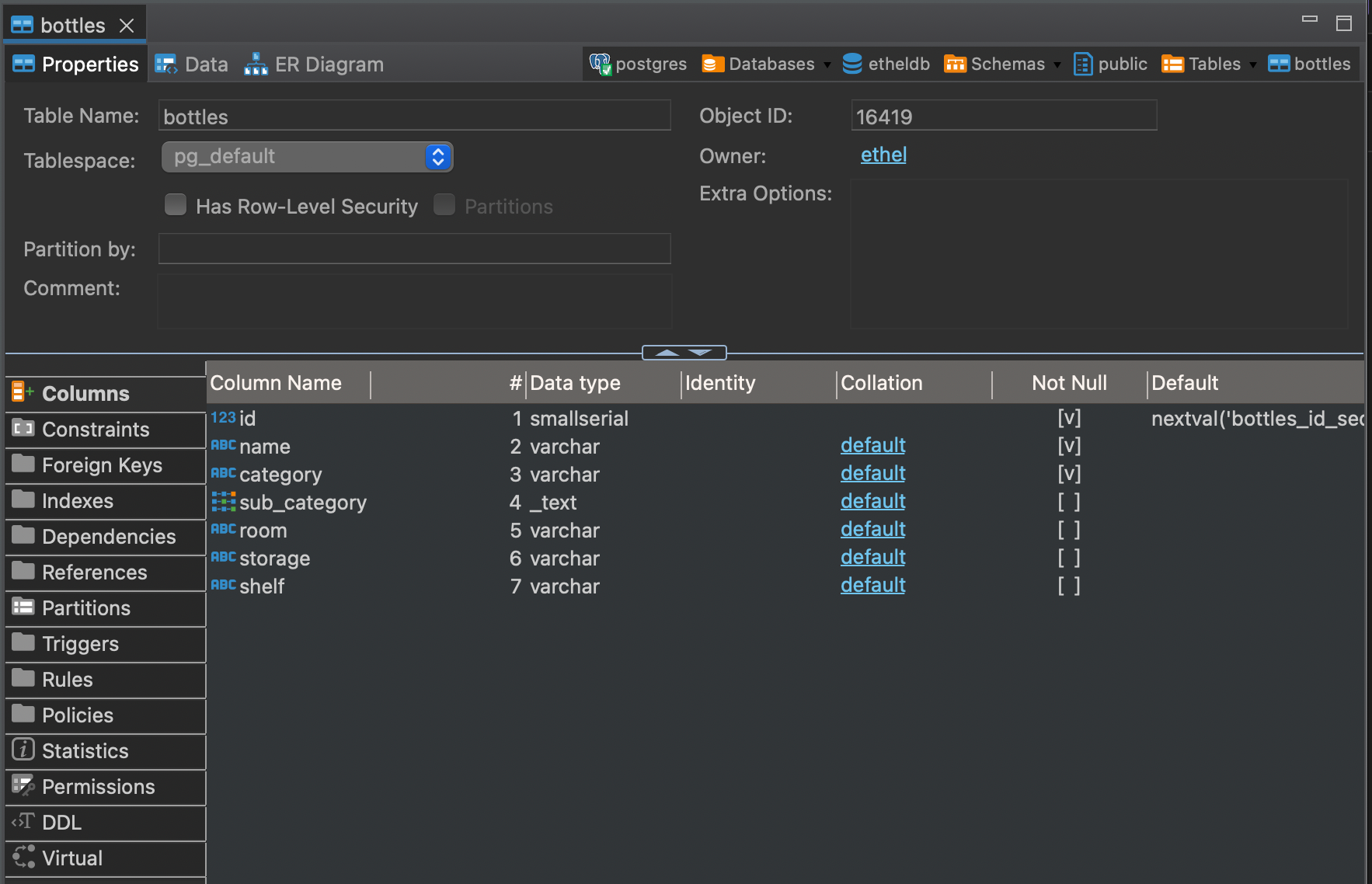
Fabulous. We know have a SQL table representing our core data structure of bottles. Now to actually do the thing and by do the thing I mean connect our application to our database! Well, I didn't make it as far as I expected but wow, have I done alot. At this point, I started realizing my struct typing on my serialized Bottle struct are going to get me in to trouble... Sigh. Next time, I will go through some of the changes I had to make in order to make my data structures play better with the "easy" style of serialization offered by combining serde and Diesel.
Homemade Piña Coladas
Okay so here comes another departure from my normal beer review. I had a can of unsweetened coconut cream about to go bad and a couple of cans of pineapple bits. So I decided to put together some summer delight in some piña coladas! I really hate watered down coladas, so I took the long (but much tastier) route to making the blended beverage:
I put my coconut cream with drained pineapple bits (retaining the pineapple juice for something else, don't let the goodness go to waste) in my blender, along with some orange juice I had in the fridge, a bit of lemon juice and maple syrup. I very very loosely based my concoction on this recipe for Ultra-Tropical Piña Coladas from Serious Eats. I substituted several things, since the goal was to throw these together with things in the kitchen. At this point I also chucked a bottle of coconut rum in the freezer to chill down for later.
Next I blended all of my delicious ingredients together, tasted, adjusted, then put the delicious mess into a freezer safe sealable container. You're are supposed to wait around an hour until its partially frozen... I barely waited until the base was sticking to sides of the container... 😅 Feel free to be more patient... or not! They are still freaking delicious!
All I had left to do was dumping the frozen deliciousness into the blender with some ice (far less than most recipes, yay) and my chilled rum. Then I blended them up and drank all of them (with help). The only thing missing was a tiny umbrella... Not sure where they went, I definitely had some... And the other thing I missed was... taking a photo of the drink!!! I haven't forgotten a beverage photo for the blog in a long time! Oh well... Cheers everyone and I hope your summer is full of delightful treats!