
99 more Bottles for Ethel and a Wee Heavy Brew

Last time, we created our boozeparser to parse csv data in order to feed my initial attempt at bottle inventory into our database for the Ethel API. We had a set of simple requirements, and we accomplished the first two: 1) should be able to run from the command line and 2) should accept a .csv file as an argument. We also imported our models from Ethel by copying and pasting our models.rs and added a struct for our Record to aid in reading our csv file as well.
Next: let's pick a way to talk to Ethel over HTTP locally. We could go super simple and use curl via a rust wrapper. We could also choose to use a higher level HTTP client to make some parts (like JSON serialization) easier. I also wouldn't mind finding a client support a blocking protocol: I don't need asynchronous processing here, most of these items needed to be created in order due to the dependency of different records on each other (such as the Bottle table relying upon category, subcategory, as well as storage).
After poking around and doing some research, plus looking at some documentation for different prospective crates on crates.io, I decided to trying reqwest, with the json and blocking features added in our Cargo.toml.
reqwest = { version = "0.12.3", features = ["json", "blocking"] }Adding reqwest to Cargo.toml
I added a GET call using reqwest to our root of the API for Ethel, knowing it would respond with 'hello world', and printed this into our application to test our call (making sure I had Ethel running locally). I added a new function create_categories to hold our new request (knowing we will probably get some warnings due to not using Results):
fn create_categories() -> Result<(), reqwest::Error> {
let body = reqwest::blocking::get("http://127.0.0.1:8000")?
.text()?;
println!("body = {body:?}");
Ok(())
}main.rs -> create_categories stub with hello world to Ethel
Let's add a call after parsing our csv then build and run our code:
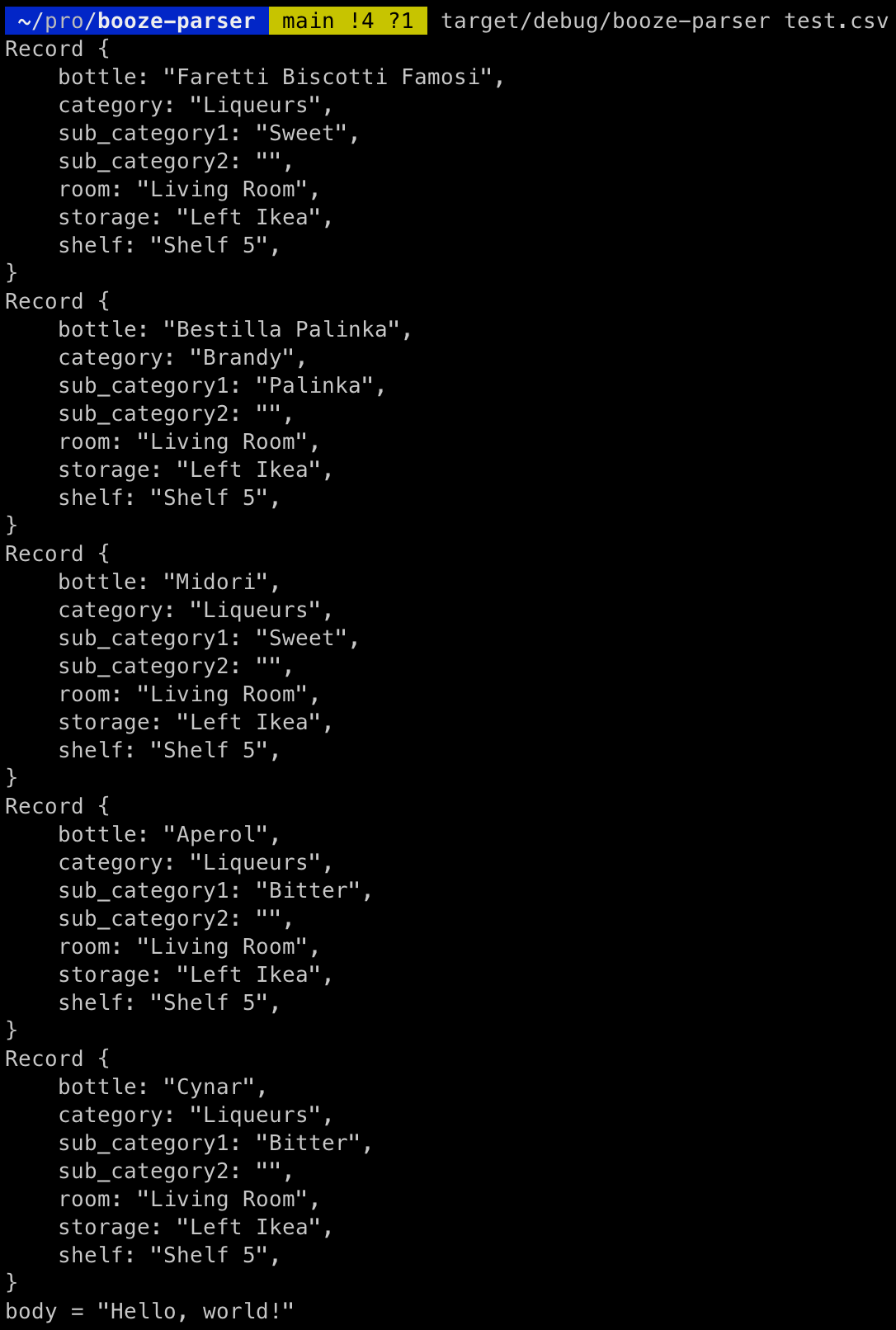
Success! You can see the output of the body of our request to Ethel yields our expected "Hello, world!" output from our root function we created waaaaaay back in our first experiments with Rocket and Rust Part II. Now we can start actually doing things.
Okay okay... I may have jumped ahead. First, we should make sure we have our results properly de-duped into arrays to create after we imported our models. Then we can feed each list (in dependency order, Categories, then Storage, then Sub Categories, then, finally, Bottles which rely upon the others). Another edge case I want to discuss is whether I want to worry about pulling existing records to check for existence, or assume a "clean" db on running the parser. Decisions, decisions...
Let's make note of it, then move on for now. My choices are either to pull the entire existing list for comparison or to create a "search by name" APIs in Ethel which do not exist today. I could also add a unique constraint on the name for bottles, as well, and catch duplicate issues on create... Okay I said we would move on for now, moving on 😅.
Let's focus on how to get our lists of records. I decided to use the HashSet collection type to gather up my individual collections of records. Using HashSet provides some additional advantages beyond using Vec: mainly, it handles duplicates for us (will just replace the old with the new version of the same entry). This does require some additions to our models we want to create HashSets for, though, as we need to support Eq, PartialEq, and Hash in order to support the functionality of our chosen collection.
It's been awhile since we looked at the entirety of main.rs. Let's see what our code looks like with our new HashSet for categories and updating our create_categories function to actually call our real API!
use clap::Parser;
use std::{collections::{HashMap, HashSet}, error::Error, process};
pub mod models;
use crate::models::{Record, NewCategory, Category};
const API_URL: &str = "http://127.0.0.1:8000";
#[derive(Parser)]
struct Cli {
path: std::path::PathBuf,
}
fn boozeparse(client: reqwest::blocking::Client) -> Result<(), Box<dyn Error>> {
let args = Cli::parse();
let mut rdr = csv::Reader::from_path(args.path)?;
let mut new_categories: HashSet<NewCategory> = HashSet::new();
// let mut sub_categories: HashSet<NewSubCategory> = HashSet::new();
for result in rdr.deserialize() {
let record: Record = result?;
println!("{:#?}", record);
new_categories.insert(NewCategory { name: record.category });
}
let created_categories = create_categories(client, new_categories);
Ok(())
}
fn create_categories(client: reqwest::blocking::Client, new_categories: HashSet<NewCategory>) -> Result<HashMap<String, Category>,reqwest::Error> {
let mut categories: HashMap<String, Category> = HashMap::new();
for category in &new_categories {
let response = client.post(format!("{API_URL}/categories"))
.json::<NewCategory>(category)
.send()?;
let created: Category = response.json().unwrap();
categories.insert(category.name.to_string(), created);
}
Ok(categories)
}
fn main() {
let client = reqwest::blocking::Client::new();
if let Err(err) = boozeparse(client) {
println!("error running booze-parser: {}", err);
process::exit(1);
}
}main.rs creating categories
I made some decisions while writing this section of code: I decided to maintain a HashMap of all the created categories to reference by name later (we will need the real database id's of our categories to create sub-categories, for example) and will try this pattern for all of the models. Let's do the thing!
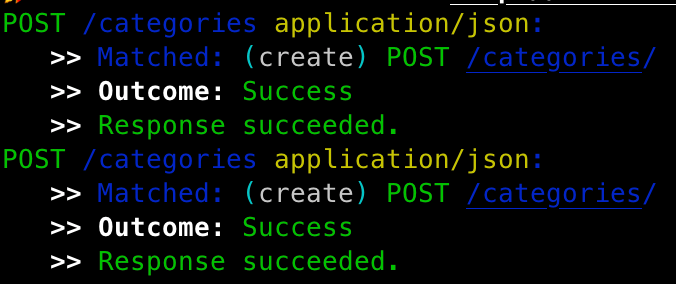
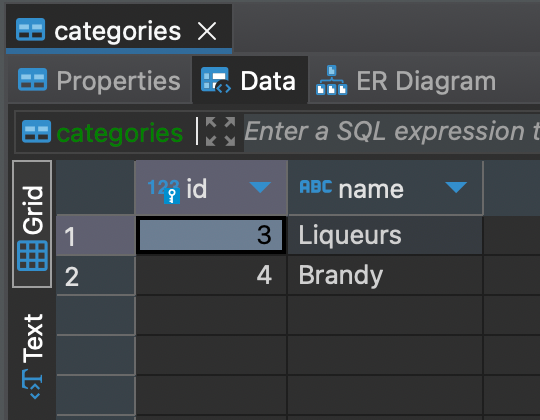
Success! Alright, not we are going to run into our problem from earlier: how do we make sure not to create categories already created in the database. I could just clear the db again... but in the case of a partial failure, it would be really nice to be able to rerun the script and only have to create things we hadn't previously. I am going to add a call to Ethel to populate my maps.
fn get_categories(client: reqwest::blocking::Client) -> Result<HashMap<String, Category>,reqwest::Error> {
let mut existing_categories: HashMap<String, Category> = HashMap::new();
let response = client.get(format!("{API_URL}/categories")).send()?;
let categories: Vec<Category> = response.json()?;
for category in categories {
existing_categories.insert(category.name.to_string(), category);
}
Ok(existing_categories)
}get_categories function to retrieve existing categories from Ethel
I am not in love with this function and I may revisit it, but it is super readable, so I will take it. This makes the same kind of HashMap<String, Category> so we can easily lookup the categories by the name of the category from the csv, since this is all we have. Then we simply have to add a check to see if the key already exists in our HashMap before adding to our HashSet of categories to create!
if !categories.contains_key(&record.category) {
new_categories.insert(NewCategory { name: record.category });
}Excerpt from boozeparse function for parsing serialized csv
Finally, when the new categories are created, I can extend my existing HashMap containing my existing categories with the new HashMap of created ones!
categories.extend(create_categories(client.clone(), new_categories)?);Now we have a model for retrieving existing records. Let's do the same for our other records! While starting to fiddle with my sub category creation I had another realization. A real face palm moment. If I go down the path of gathering all the information first then creating records in batches... It means I would need to create a new kind of storage for the structs which reference other tables... For example, the NewSubCategory struct requires and ID for a the category.
I have a few choices: I could store the Records I serialize from CSV then iterate in memory, doing a pass on the records for each struct. Another option is creating an new way to store the references with the string values temporarily then doing a lookup once I create the records in a cascading fashion. Finally, I could do all the creation inline while deserializing the Record in the file.
The last one would be "least code" but also the most likely to crash or run into issues. I am waffling on just doing it this way because, as discussed early in this project, this is only meant to "run once" in order to parse some data into my database then never have to touch it again. I think since I added the check for not recreating records I already I have, rerunning it is also low risk, and only hurting myself and my machine.
I would never recommend doing something like this in production, for sure, but this is a great example of KISS. There is no need for me to make a really awesome performant little application right now: I just need to get the damn data in the damn database 😂. So, to be clear, my current proposal is structuring my app like this:
- Look up existing records to reference ids for new creation and prevent duplication
- Parse the CSV file
- While deserializing each record, create each needed value inline:
- Category
- Sub Category
- Storage
- Bottle
Alright, let's repurpose our category code and start creating the other functions we need! This means we can get rid of our HashSet implementation for uniqueness as well, since we can just check if the HashMap of the individual struct types has the key equivalent to the name of the field on the Record.
While I could probably do some more cleanup, here is my eventual, working result! I did into a fun problem around what key to use the for storage: I can't just use the name, because the name on the storage is not unique. My shortcut was to cram the name, room, and shelf all together to create a unique hash key and use it. I will also say... I am not proud of having this all crammed on one file 😅.
fn boozeparse(client: reqwest::blocking::Client) -> Result<(), Box<dyn Error>> {
let args = Cli::parse();
let mut rdr = csv::Reader::from_path(args.path)?;
let mut categories = get_categories(client.clone())?;
let mut sub_categories: HashMap<String, SubCategory> = get_sub_categories(client.clone())?;
let mut storage: HashMap<String, Storage> = get_storage(client.clone())?;
let mut bottles: HashMap<String, Bottle> = get_bottles(client.clone())?;
for result in rdr.deserialize() {
let record: Record = result?;
let category_id: i16;
let storage_id: i16;
let mut sub_category_ids: Vec<Option<i16>> = Vec::new();
// Create Category
if !categories.contains_key(&record.category) {
let created_category = create_category(client.clone(), NewCategory { name: record.category })?;
categories.insert(created_category.name.to_string(), created_category.clone());
category_id = created_category.id;
println!("Created Category {:?}", created_category);
} else {
match categories.get(&record.category) {
Some(cat) => category_id = cat.id.clone(),
None => return Err(Box::from(format!("Error getting category {}", &record.category)))
}
}
//Create Subcat 1
if !&record.sub_category1.is_empty() && !sub_categories.contains_key(&record.sub_category1) {
let created_sub = create_sub_category(client.clone(), NewSubCategory { category_id: category_id, name: record.sub_category1 })?;
sub_categories.insert(created_sub.name.to_string(), created_sub.clone());
sub_category_ids.push(Some(created_sub.id));
println!("Created Sub Category {:?}", created_sub);
} else if !&record.sub_category1.is_empty() {
match sub_categories.get(&record.sub_category1) {
Some(sub) => sub_category_ids.push(Some(sub.id.clone())),
None => return Err(Box::from(format!("Error getting sub category {}", &record.sub_category1)))
}
}
//Create Subcat 2
if !&record.sub_category2.is_empty() && !sub_categories.contains_key(&record.sub_category2) {
let created_sub = create_sub_category(client.clone(), NewSubCategory { category_id: category_id, name: record.sub_category2 })?;
sub_categories.insert(created_sub.name.to_string(), created_sub.clone());
sub_category_ids.push(Some(created_sub.id));
println!("Created Sub Category {:?}", created_sub);
} else if !&record.sub_category2.is_empty() {
match sub_categories.get(&record.sub_category2) {
Some(sub) => sub_category_ids.push(Some(sub.id.clone())),
None => return Err(Box::from(format!("Error getting sub category {}", &record.sub_category2)))
}
}
// Create Storage
let storage_key = format!("{}{}{}", &record.storage, &record.room, &record.shelf);
if !storage.contains_key(&storage_key) {
let created_storage = create_storage(client.clone(), NewStorage { name: record.storage, room: record.room, shelf: record.shelf })?;
storage.insert(storage_key.to_string(), created_storage.clone());
storage_id = created_storage.id;
println!("Created Storage {:?}", created_storage);
} else {
match storage.get(&storage_key) {
Some(store) => storage_id = store.id.clone(),
None => return Err(Box::from(format!("Error getting storage id {}", &storage_key)))
}
}
// Create Bottle
if !bottles.contains_key(&record.bottle) {
let created_bottle = create_bottle(client.clone(), NewBottle { name: record.bottle, category_id: category_id, sub_category_ids: Some(sub_category_ids), storage_id: storage_id })?;
bottles.insert(created_bottle.name.to_string(), created_bottle.clone());
println!("Created Bottle {:?}", created_bottle);
}
}
Ok(())
}boozeparse function from main.rs
I decided to have the script output the items it created, as well as print some more sensible error messages if I ran into an issue looking up a key for some reason (the more verbose error handling was a result of not quite getting my compound hash key for the storage right the first time).
After running the script a couple times (yay, dupe checking!) I have the five records in my test csv in my database! Now when we call the bottles endpoint in Ethel, we get the following response:
[
{
"id": 2,
"name": "Faretti Biscotti Famosi",
"category_id": 3,
"sub_category_ids": [
1
],
"storage_id": 1
},
{
"id": 3,
"name": "Bestilla Palinka",
"category_id": 4,
"sub_category_ids": [
2
],
"storage_id": 1
},
{
"id": 4,
"name": "Midori",
"category_id": 3,
"sub_category_ids": [
1
],
"storage_id": 1
},
{
"id": 5,
"name": "Aperol",
"category_id": 3,
"sub_category_ids": [
3
],
"storage_id": 1
},
{
"id": 6,
"name": "Cynar",
"category_id": 3,
"sub_category_ids": [
3
],
"storage_id": 1
}
]Response from Ethel /bottles GET
Success! Before we feed the entire csv in, I want to test one more thing: a record with two sub categories. I updated my csv file to the following:
bottle,category,sub_category1,sub_category2,room,storage,shelf
House Aged Glendalough Poitín,Whiskey,Irish,Poitín,Dining Room,Buffet,Center Top
Updated test.csv with a multi-sub-category record

Perfect! Everything appears to be working as expected. Let's feed it the real csv now... Okay that is a lot of terminal output! But everything worked, and now I officially have all of the original bottle list of 129 bottles into my database and available to my API.
Stemma Brewing's Wee Heavy Scotch Ale
We had a bit of cold snap recently in the PNW. Some folks call it "June-uary", the last gasp of Pacific moisture smacking into the coast before the drier, sunny summer. I like this weather, it's part of the reason I stay. It also let's me not feel like a complete weirdo while I decide to drink some heavy rich beer usually relegated to the darker winter months!
Stemma Brewing in Bellingham, WA has some stellar beers. I am a regular drinker of their coffee oatmeal stout! Recently a local store had special edition beer from them as a part of their Staff Animation series, Beers with Captain Mark: a wee heavy scotch ale weighing in at 9.8% ABV. It is rich, boozy, and very very yummy. I am glad it's only a small can!